오픈소스 Tesseract 를 사용해서 쉽고 간편하게 text추출 하는 애플리케이션을 구현했다.
해당 라이브러리를 활용한 코딩은 구글링하면 많이 나온다.
그래도 내가 한 것을 기록하자면.
gradle, java17, springBoot3.2.4 환경으로 개발했다.
1. 아래와 같이 tesseract 라이브러리를 추가.
dependencies {
implementation 'net.sourceforge.tess4j:tess4j:5.3.0'
}
2. 서비스단에 소스.
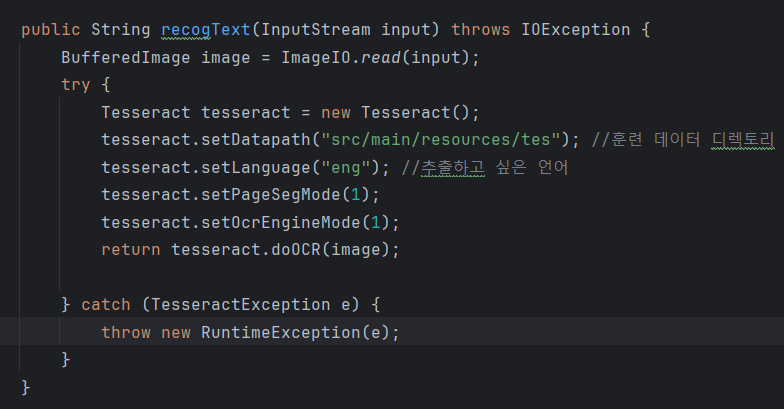
tesseract.setHocr(true);//결과를 String이 아닌 html 형태로도 받을 수 있다.
tesseract.doOCR(imageFile, new Rectangle(1200, 200)); // java.awt.Rectangle로 객체를 만들어 지정영역에서만 텍스트를 추출할 수도 있다.
**무작정 소스만 따라하다 발생한 error들.
<에러1>
-서버 에러 로그
Error opening data file src/main/resources/tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
-클라이언트 응답
<해결>
tesseract 객체에 datapath 지정한 곳에 폴더가 있어야 하고 그 안에 데이터 파일도 있어야 한다.
그렇지 않으면 클라이언트에 응답값도 500에러가 떨어진다.
**데이터 파일 구한 곳
https://github.com/tesseract-ocr/tessdata/
<에러2>
-서버 에러 로그
Warning: Parameter not found: enable_new_segsearch
Error: LSTM requested, but not present!! Loading tesseract.
Error opening data file src/main/resources/tes/osd.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'osd'
Tesseract couldn't load any languages!
Warning: Auto orientation and script detection requested, but osd language failed to load
Estimating resolution as 237
-클라이언트에 응답.(응답 잘 감. 텍스트 추출 모두 됨. )
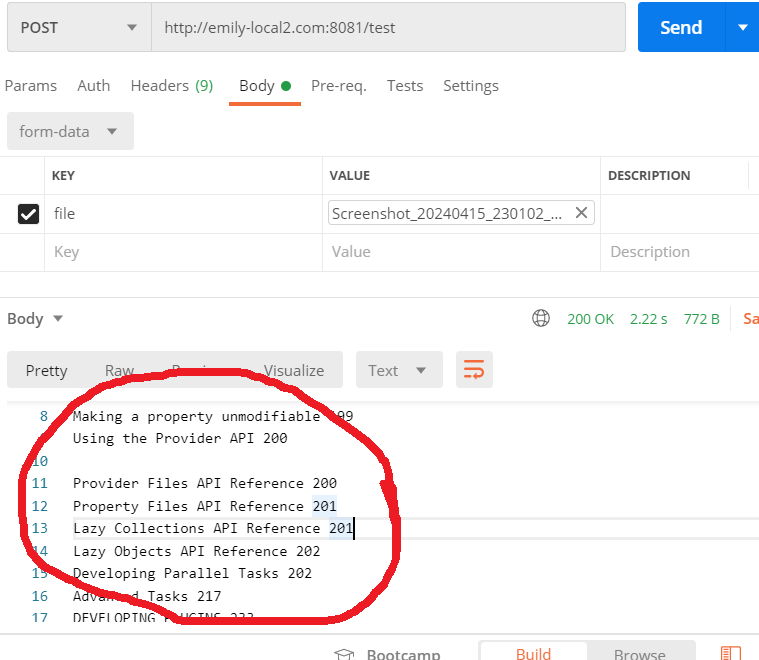
<해결>
트레인할 데이터 파일이 부족했을 때 저 에러로그가 나오는 것 같다.
에러에 빨간 줄 친 부분에 해당하는 osd.traindata 파일을 넣어주면
또 저런 식으로 부족한 데이터 파일을 찾아 에러로그가 찍힌다.
하지만 원하는 응답은 return 되었다.
트레인 데이터를 모두 넣어주면 에러가 나지 않는다.
'JAVA' 카테고리의 다른 글
| java 설치, 환경변수 설정 이유와 방법. (0) | 2024.03.25 |
|---|---|
| <? extends 클래스> (0) | 2022.05.17 |